Deep Learning on Distributed Machines
0.0.0.0.1 Utilizing distributed machines to scale deep learning research models.
0.1 Scalable Deep Learning on Distributed Machines
Collaborators: USC CARC (Iman Rahbari and Hao Ji)
Deep Learning models are becoming more complex and computationally demanding. However, popular packages to conduct the underlying calculations are designed to work only on a single GPU, or at most on one compute node. This has posed difficulties for many research teams to scale their research models and test them in real-life applications. Moreover, there are many emerging computing architectures that promise improved efficiencies for deep learning applications, but properly assessing these technologies for individual research teams is a challenging task that is mostly left unaddressed.
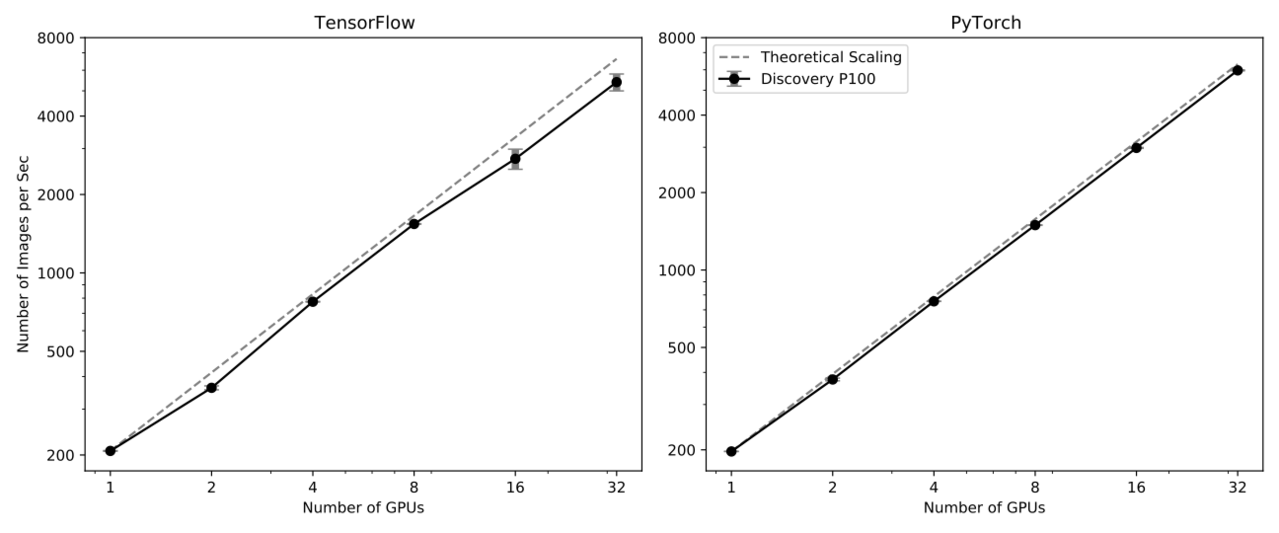
Above is the strong scaling plot using these tests on Discovery nodes with 2x P100 Nvidia GPUs
In this project, the Horovod package it used as an additional tool for training Deep Learning models. The collaborators use popular Deep Learning platforms across many compute nodes on CARC’s in-house cluster with different Nvidia GPUs with (and without) the nvlink. They then extend the scope of their work to assess the emerging architectures, such as Gaudi Accelerators, to assess these configurations for different workflows.